My research focuses on physical intelligence — enabling intelligent systems to perceive, reconstruct, and reason about the physical world through non-contact, privacy-preserving, and ubiquitous sensing modalities. I develop sensing and learning frameworks that transform sparse physical signals into structured, human-centric spatial representations, with applications in human-aware buildings, ubiquitous interaction, and non-intrusive health monitoring.
Currently, I am working on the following topics:
Thermal Array–Based Spatial Sensing Intelligence: Developing physics-guided and learning-based frameworks that elevate low-resolution thermal array measurements into 3D spatial representations for human detection, ranging, reconstruction, interaction, and building-scale occupancy analytics, with strong privacy and cost advantages.
Physics-Grounded and Interpretable Learning Models: Designing physics-learning co-models that incorporate physical principles, geometric constraints, and biomechanical structure into deep learning models to improve robustness, interpretability, and generalizability.
Multi-modal and Cross-Modal Representation Learning: Aligning and fusing heterogeneous physical signals from different modalities — including thermal, RF, WiFi, acoustic, and inertial signals — to build unified representation spaces exposes richer physical structure than any single modality alone, supported by multi-modal datasets and representation alignment methods.
I am open for any discussions and collaborations. Please feel free to contact me with zhangxie289 at gmail dot com.
News
2, July 2026 One paper is conditionally accepted by MobiCom’26!
1, July 2026 One paper is accepted by Ubicomp’26!
4, May 2026 Received the 13th HLF Travel Grant Award
25, April 2026 Honored to be recognized as a MobiSys’26 Rising Star
15, April 2026 Chosen as a Young Researcher for the 13th Heidelberg Laureate Forum (HLF)
If you’d like to share my work and need slide decks, feel free to contact me with zhangxie289 at gmail dot com.
Preprints
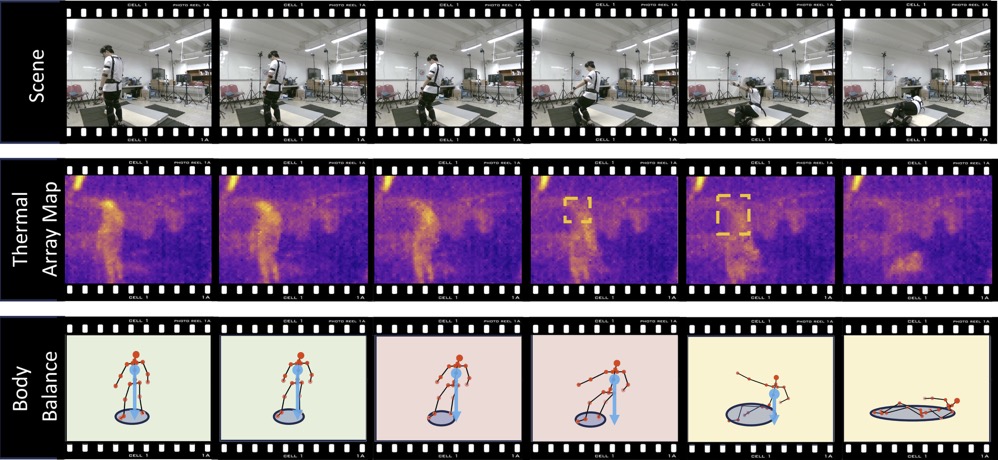
TaFall: Balance-Informed Fall Detection via Passive Thermal Sensing
Li, Chengxiao and Zhang, Xie and Zhu, Wei and Jiang, Yan and Wu, Chenshu
arXiv, 2026
@misc{liTaFallBalanceInformedFall2026,
title = {{{TaFall}}: {{Balance-Informed Fall Detection}} via {{Passive Thermal Sensing}}},
shorttitle = {{{TaFall}}},
author = {Li, Chengxiao and Zhang, Xie and Zhu, Wei and Jiang, Yan and Wu, Chenshu},
year = {2026},
month = apr,
number = {arXiv:2604.09693},
eprint = {2604.09693},
primaryclass = {cs},
publisher = {arXiv},
doi = {10.48550/arXiv.2604.09693},
urldate = {2026-04-30},
archiveprefix = {arXiv},
file = {https://arxiv.org/abs/2604.09693},
abbreviated = {Arxiv'26, under review},
thumbnail_path = {/assets/thumbnail_files/tafall.jpg}
}
Falls are a major cause of injury and mortality among older adults, yet most incidents occur in private indoor environments where monitoring must balance effectiveness with privacy. Existing privacy-preserving fall detection approaches, particularly those based on radio frequency sensing, often rely on coarse motion cues, which limits reliability in real-world deployments. We introduce TaFall, a balance-informed fall detection system based on low-cost, privacy-preserving thermal array sensing. The key insight is that TaFall models a fall as a process of balance degradation and detects falls by estimating pose-driven biomechanical balance dynamics. To enable this capability from low-resolution thermal array maps, we propose (i) an appearance-motion fusion model for robust pose reconstruction, (ii) physically grounded balance-aware learning, and (iii) pose-bridged pretraining to improve robustness. TaFall achieves a detection rate of 98.26% with a false alarm rate of 0.65% on our dataset with over 3,000 fall instances from 35 participants across diverse indoor environments. In 27 day deployments across four homes, TaFall attains an ultra-low false alarm rate of 0.00126% and a pilot bathroom study confirms robustness under moisture and thermal interference. Together, these results establish TaFall as a reliable and privacy-preserving approach to fall detection in everyday living environments.
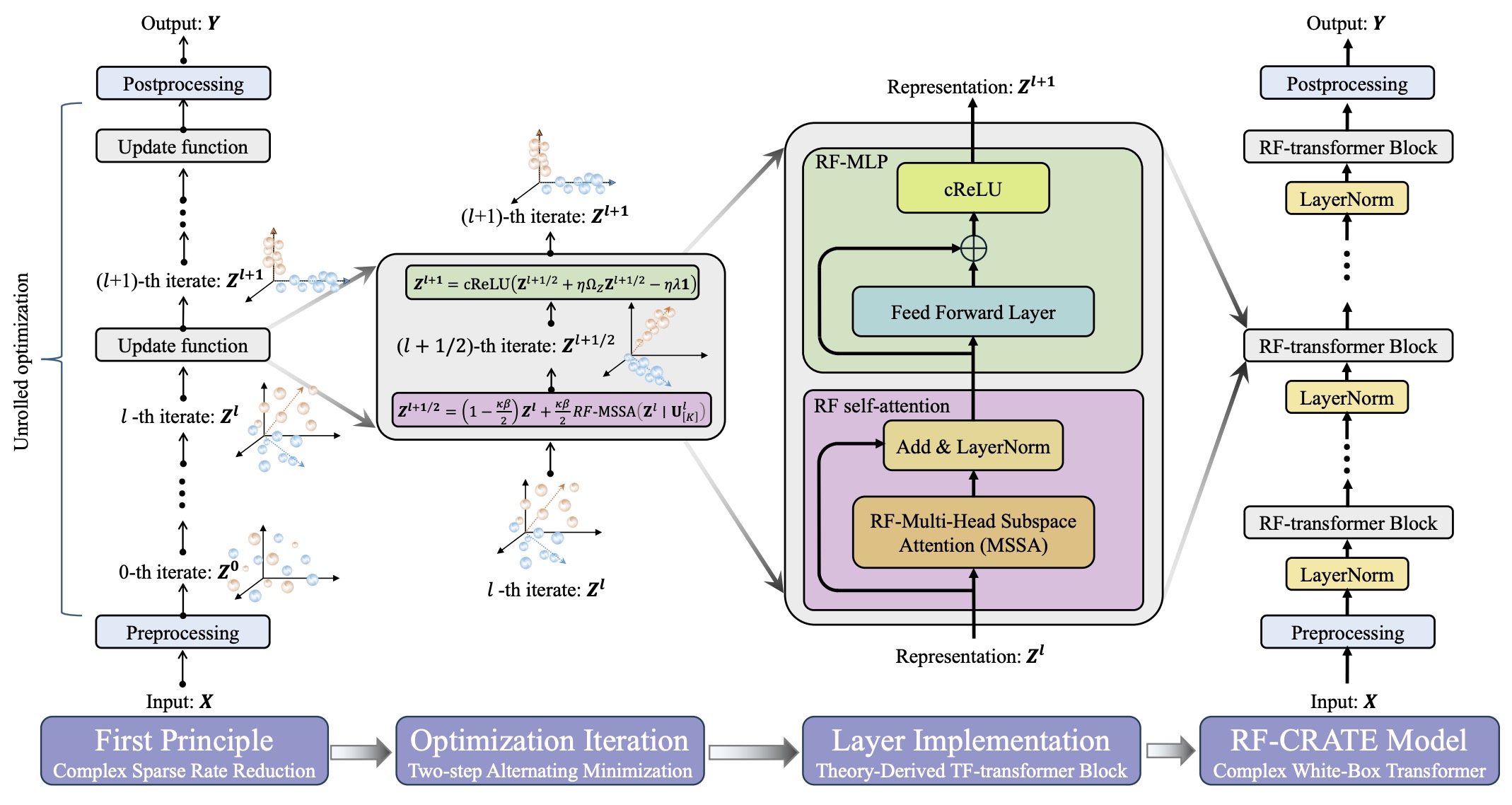
Unlocking Interpretability for RF Sensing: A Complex-Valued White-Box Transformer
Zhang, Xie and Wang, Yina and Wu, Chenshu
arXiv, 2025
@misc{zhang2025unlockinginterpretabilityrfsensing,
title = {Unlocking Interpretability for RF Sensing: A Complex-Valued White-Box Transformer},
author = {Zhang, Xie and Wang, Yina and Wu, Chenshu},
year = {2025},
eprint = {2507.21799},
publisher = {arXiv},
primaryclass = {cs.LG},
url = {https://arxiv.org/abs/2507.21799},
file = {https://arxiv.org/abs/2507.21799},
abbreviated = {Arxiv'25, under review},
thumbnail_path = {/assets/thumbnail_files/rfcrate.jpg}
}
The empirical success of deep learning has spurred its application to the radio-frequency (RF) domain, leading to significant advances in Deep Wireless Sensing (DWS). However, most existing DWS models function as black boxes with limited interpretability, which hampers their generalizability and raises concerns in security-sensitive physical applications. In this work, inspired by the remarkable advances of white-box transformers, we present RF-CRATE, the first mathematically interpretable deep network architecture for RF sensing, grounded in the principles of complex sparse rate reduction. To accommodate the unique RF signals, we conduct non-trivial theoretical derivations that extend the original real-valued white-box transformer to the complex domain. By leveraging the CR-Calculus framework, we successfully construct a fully complex-valued white-box transformer with theoretically derived self-attention and residual multi-layer perceptron modules. Furthermore, to improve the model’s ability to extract discriminative features from limited wireless data, we introduce Subspace Regularization, a novel regularization strategy that enhances feature diversity, resulting in an average performance improvement of 19.98% across multiple sensing tasks. We extensively evaluate RF-CRATE against seven baselines with multiple public and self-collected datasets involving different RF signals. The results show that RF-CRATE achieves performance on par with thoroughly engineered black-box models, while offering full mathematical interpretability. More importantly, by extending CRATE to the complex domain, RF-CRATE yields substantial improvements, achieving an average classification gain of 5.08% and reducing regression error by 10.34% across diverse sensing tasks compared to CRATE. RF-CRATE is fully open-sourced at: https://github.com/rfcrate/RF_CRATE.
Conference proceedings
From Body Heat to Behavioral Horizons: Spatial Sensing Intelligence with Thermal Arrays
Zhang, Xie
Proceedings of the 24th Annual International Conference on Mobile Systems, Applications and Services Companion, 2026, pp. 122–123
@inproceedings{rising_star_mobisys2026,
author = {Zhang, Xie},
title = {From Body Heat to Behavioral Horizons: Spatial Sensing Intelligence with Thermal Arrays},
year = {2026},
isbn = {9798400727115},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi-org.eproxy.lib.hku.hk/10.1145/3812835.3814826},
doi = {10.1145/3812835.3814826},
booktitle = {Proceedings of the 24th Annual International Conference on Mobile Systems, Applications and Services Companion},
pages = {122–123},
numpages = {2},
keywords = {spatial intelligence, human sensing, thermal array},
location = {University of Cambridge, Cambridge, United Kingdom},
series = {MobiSys Companion '26},
abbreviated = {MobiSys'26 Rising Star},
file = {/papers/rising_star.pdf},
thumbnail_path = {/assets/thumbnail_files/rising_star.jpg}
}
While humans spend most of their lives indoors, our built environments remain largely blind to their behavior. My research establishes Spatial Sensing Intelligence, leveraging low-cost, passive thermal arrays for non-intrusive, privacy-preserving human perception. To overcome the limited spatial resolution of passive heat signals, I develop physics-informed deep learning frameworks that transform 2D thermal maps into high-fidelity 3D body representations. These geometric representations directly unlock diverse applications, including fine-grained around-device control, sleep monitoring, and fall detection, validated by a 256-day real-world campus deployment. Moving forward, I extend this vision through interpretable modeling and multi-modal sensing, paving the way for natively human-aware indoor spaces.
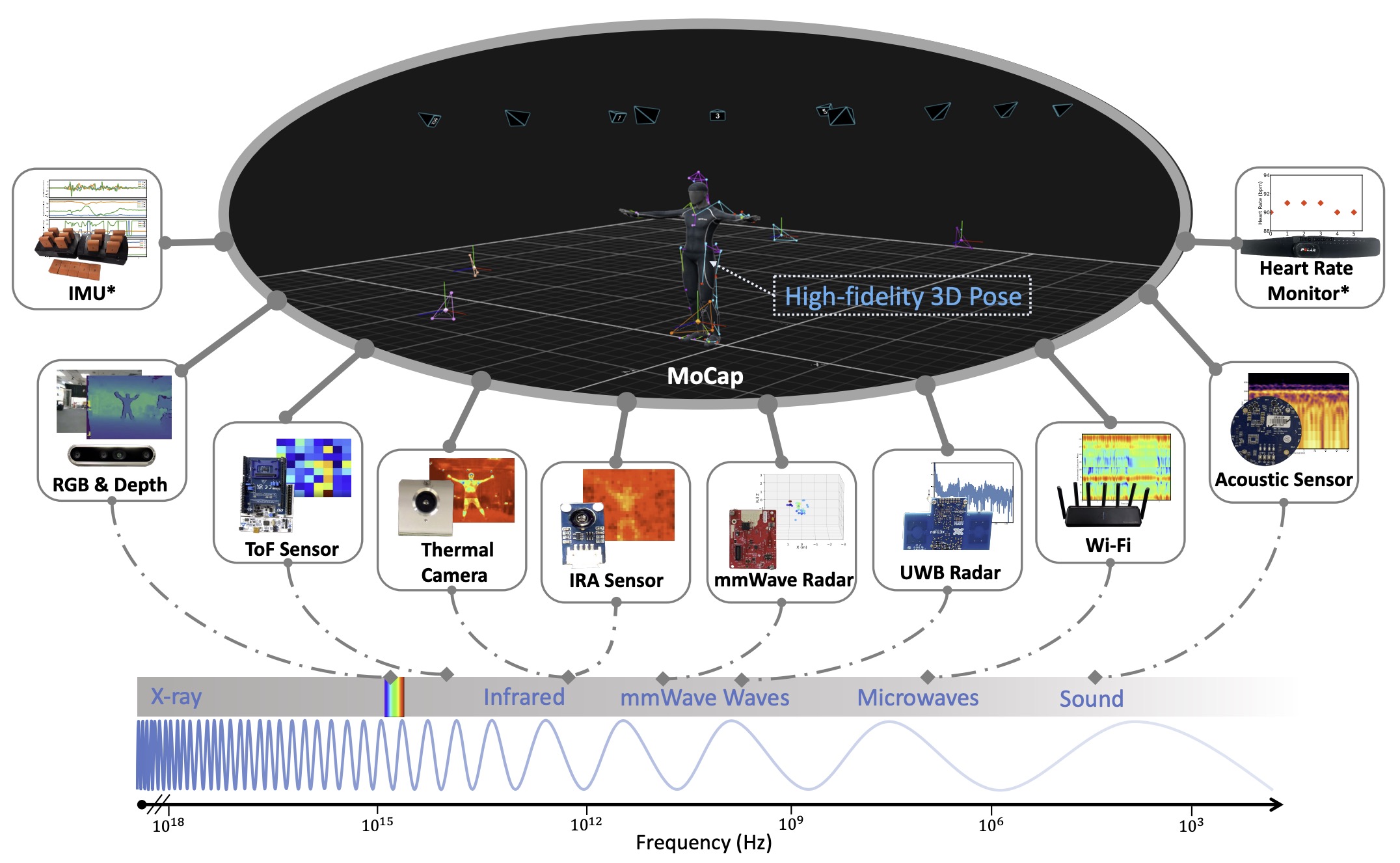
OctoNet: A Large-Scale Multi-Modal Dataset for Human Activity Understanding Grounded in Motion-Captured 3D Pose Labels
*Yuan, Dongsheng and *Zhang, Xie and Hou, Weiying and Lyu, Sheng and Yu, Yuemin and Yu, Luca Jiang-Tao and Li, Chengxiao and Wu, Chenshu
The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
*Equal contribution
@inproceedings{yuanOctoNetLargeScaleMultiModal2025,
title = {{{OctoNet}}: {{A Large-Scale Multi-Modal Dataset}} for {{Human Activity Understanding Grounded}} in {{Motion-Captured 3D Pose Labels}}},
shorttitle = {{{OctoNet}}},
booktitle = {The {{Thirty-ninth Annual Conference}} on {{Neural Information Processing Systems Datasets}} and {{Benchmarks Track}}},
author = {$^*$Yuan, Dongsheng and $^*$Zhang, Xie and Hou, Weiying and Lyu, Sheng and Yu, Yuemin and Yu, Luca Jiang-Tao and Li, Chengxiao and Wu, Chenshu},
year = {2025},
month = oct,
urldate = {2025-11-09},
langid = {english},
note = {$^*$Equal contribution},
abbreviated = {NeurIPS'25},
code = {https://aiot-lab.github.io/OctoNet/},
file = {https://openreview.net/pdf?id=z3TftXOizf},
thumbnail_path = {/assets/thumbnail_files/octonet.jpg}
}
We introduce OctoNet, a large-scale, multi-modal, multi-view human activity dataset designed to advance human activity understanding and multi-modal learning. OctoNet comprises 12 heterogeneous modalities (including RGB, depth, thermal cameras, infrared arrays, audio, millimeter-wave radar, Wi-Fi, IMU, and more) recorded from 41 participants under multi-view sensor setups, yielding over 67.72M synchronized frames. The data encompass 62 daily activities spanning structured routines, freestyle behaviors, human-environment interaction, healthcare tasks, etc. Critically, all modalities are annotated by high-fidelity 3D pose labels captured via a professional motion-capture system, allowing precise alignment and rich supervision across sensors and views. OctoNet is one of the most comprehensive datasets of its kind, enabling a wide range of learning tasks such as human activity recognition, 3D pose estimation, multi-modal fusion, cross-modal supervision, and sensor foundation models. Extensive experiments have been conducted to demonstrate the sensing capacity using various baselines. OctoNet offers a unique and unified testbed for developing and benchmarking generalizable, robust models for human-centric perceptual AI.
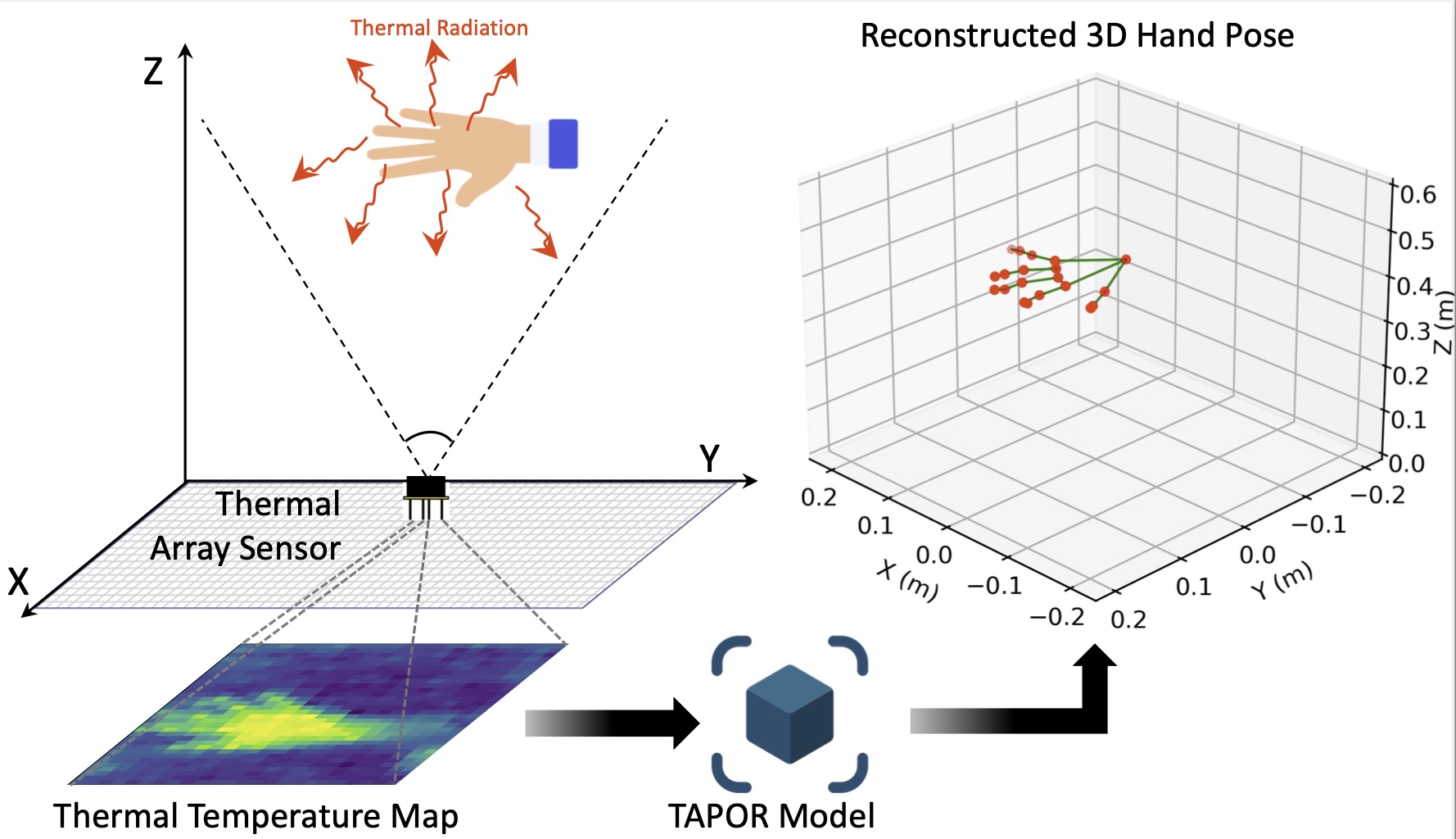
TAPOR: 3D Hand Pose Reconstruction with Fully Passive Thermal Sensing for around-Device Interactions
Zhang, Xie and Li, Chengxiao and Wu, Chenshu
Proc. ACM Interact. Mob. Wearable Ubiquitous Technol., 2025
@inproceedings{Zhangtapor2025,
title = {{{TAPOR}}: {{3D}} Hand Pose Reconstruction with Fully Passive Thermal Sensing for around-Device Interactions},
booktitle = {Proc. {{ACM Interact}}. {{Mob}}. {{Wearable Ubiquitous Technol}}.},
author = {Zhang, Xie and Li, Chengxiao and Wu, Chenshu},
year = {2025},
month = jun,
volume = {9},
doi = {https://doi.org/10.1145/3729499},
articleno = {63},
code = {https://github.com/aiot-lab/TAPOR},
demo = {https://www.youtube.com/watch?v=dRiqxPZx4zk},
file = {https://arxiv.org/pdf/2501.17585},
abbreviated = {Ubicomp'25},
thumbnail_path = {/assets/thumbnail_files/tapor.jpg}
}
This paper presents the design and implementation of TAPOR, a privacy-preserving, non-contact, and fully passive sensing system for accurate and robust 3D hand pose reconstruction for around-device interaction using a single low-cost thermal array sensor. Thermal sensing using inexpensive and miniature thermal arrays emerges with an excellent utility-privacy balance, offering an imaging resolution significantly lower than cameras but far superior to RF signals like radar or WiFi. The design of TAPOR, however, is challenging, mainly because the captured temperature maps are low-resolution and textureless. To overcome the challenges, we investigate thermo-depth and thermo-pose properties, proposing a novel physics-inspired neural network that learns effective 3D spatial representations of potential hand poses. We then formulate the 3D pose reconstruction problem as a distinct retrieval task, enabling accurate hand pose determination from the input temperature map. To deploy TAPOR on IoT devices, we introduce an effective heterogeneous knowledge distillation method, reducing computation by 377×. TAPOR is fully implemented and tested in real-world scenarios, showing remarkable performance, supported by four gesture control and finger tracking case studies. We envision TAPOR to be a ubiquitous interface for around-device control and have open-sourced it at https://github.com/aiot-lab/TAPOR.
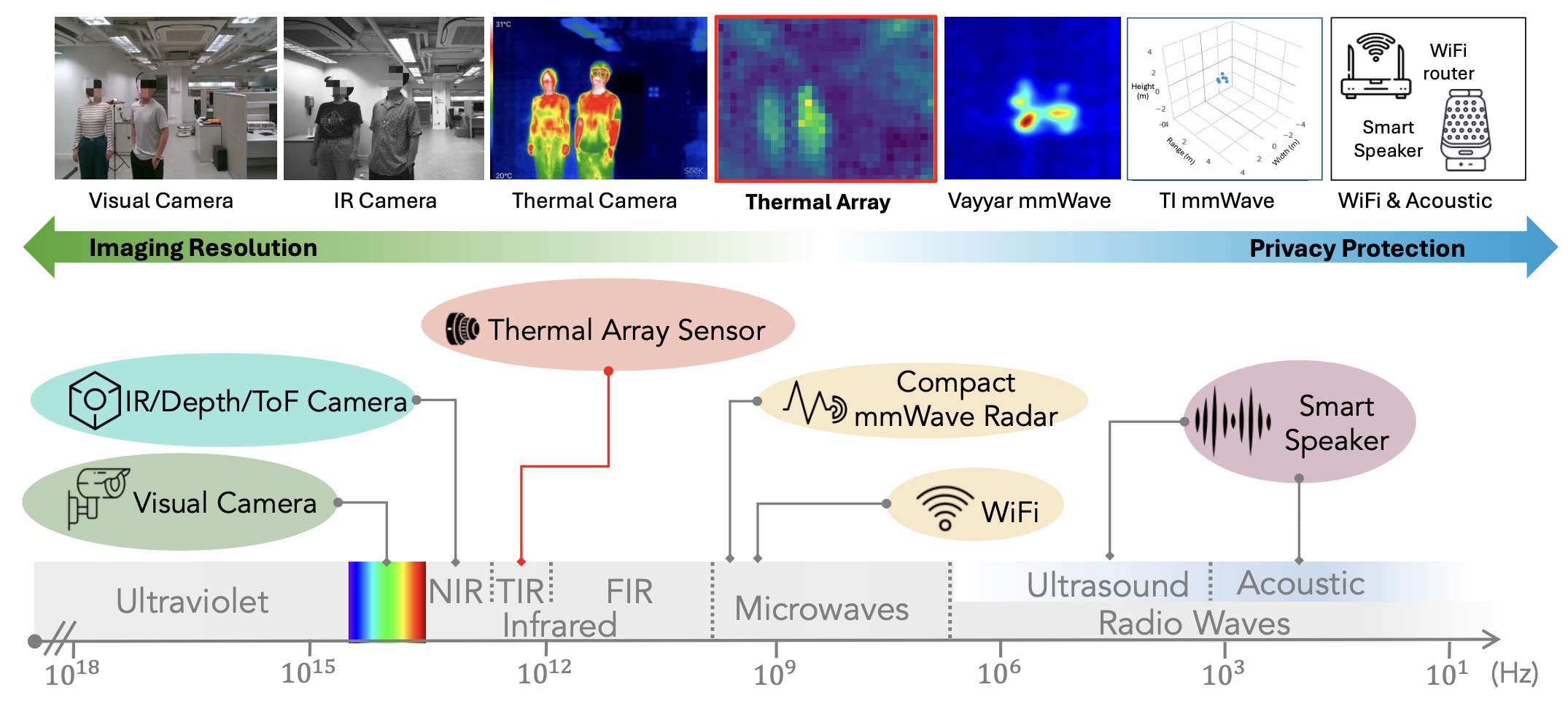
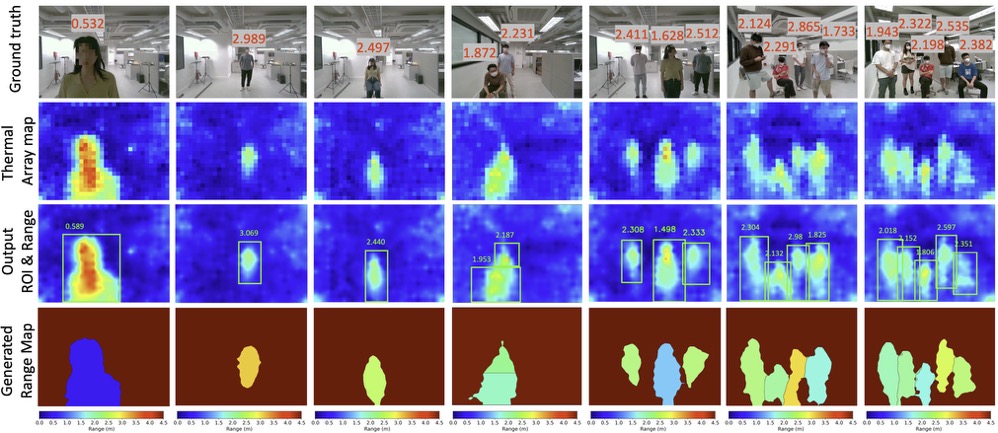
TADAR: Thermal array-based detection and ranging for privacy-preserving human sensing
Zhang, Xie and Wu, Chenshu
Proceedings of the 25th international symposium on theory, algorithmic foundations, and protocol design for mobile networks and mobile computing (MOBIHOC ’24), 2024, pp. 1–10
@inproceedings{Zhang2024TADAR,
address = {Athens, Greece},
title = {{TADAR}: {Thermal} array-based detection and ranging for privacy-preserving human sensing},
doi = {https://doi.org/10.1145/3641512.3686357},
booktitle = {Proceedings of the 25th international symposium on theory, algorithmic foundations, and protocol design for mobile networks and mobile computing ({MOBIHOC} '24)},
publisher = {ACM},
author = {Zhang, Xie and Wu, Chenshu},
year = {2024},
pages = {1--10},
code = {https://github.com/aiot-lab/TADAR},
demo = {https://youtu.be/0hGqzSYlh4o},
file = {https://arxiv.org/pdf/2409.17742},
abbreviated = {MobiHoc'24},
thumbnail_path = {/assets/thumbnail_files/tadar.jpg}
}
Human sensing has gained increasing attention in various applications. Among the available technologies, visual images offer high accuracy, while sensing on the RF spectrum preserves privacy, creating a conflict between imaging resolution and privacy preservation. In this paper, we explore thermal array sensors as an emerging modality that strikes an excellent resolution-privacy balance for ubiquitous sensing. To this end, we present TADAR, the first multi-user Thermal Array-based Detection and Ranging system that estimates the inherently missing range information, extending thermal array outputs from 2D thermal pixels to 3D depths and empowering them as a promising modality for ubiquitous privacy-preserving human sensing. We prototype TADAR using a single commodity thermal array sensor and conduct extensive experiments in different indoor environments. Our results show that TADAR achieves a mean F1 score of 88.8% for multi-user detection and a mean accuracy of 32.0 cm for multi-user ranging, which further improves to 20.1 cm for targets located within 3 m. We conduct two case studies on fall detection and occupancy estimation to showcase the potential applications of TADAR. We hope TADAR will inspire the vast community to explore new directions of thermal array sensing, beyond wireless and acoustic sensing. TADAR is open-sourced on GitHub: https://github.com/aiot-lab/TADAR.
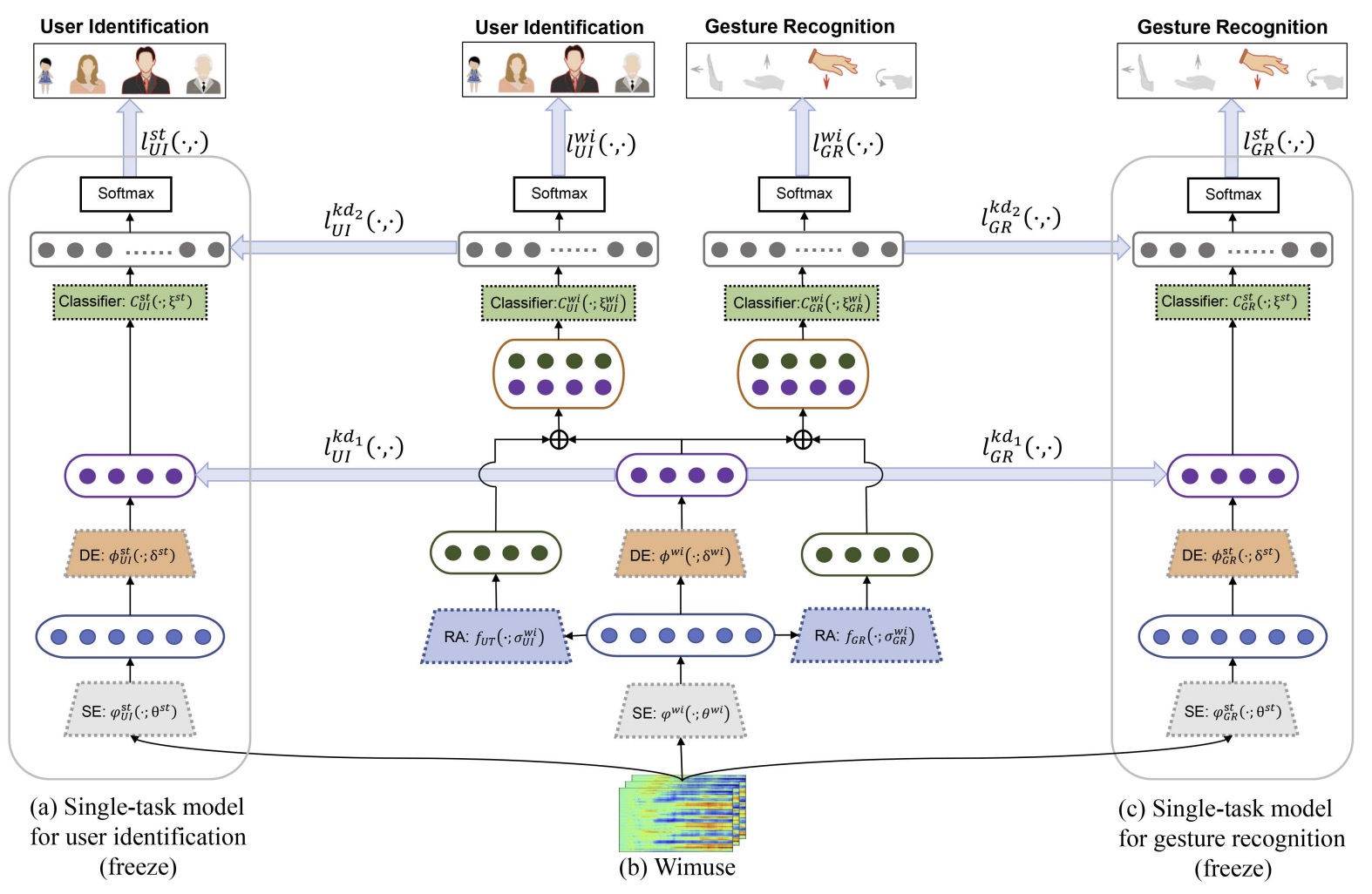
WiFi-Based Multi-task Sensing
Zhang, Xie and Tang, Chengpei and An, Yasong and Yin, Kang
Mobile and Ubiquitous Systems: Computing, Networking and Services, 2021, pp. 169–189
@inproceedings{zhangWiFiBasedMultitaskSensing2022,
title = {{{WiFi-Based Multi-task Sensing}}},
booktitle = {Mobile and {{Ubiquitous Systems}}: {{Computing}}, {{Networking}} and {{Services}}},
author = {Zhang, Xie and Tang, Chengpei and An, Yasong and Yin, Kang},
editor = {Hara, Takahiro and Yamaguchi, Hirozumi},
year = {2021},
pages = {169--189},
publisher = {Springer International Publishing},
address = {Cham},
doi = {10.1007/978-3-030-94822-1_10},
isbn = {978-3-030-94822-1},
langid = {english},
file = {https://arxiv.org/pdf/2111.14619},
code = {https://github.com/Zhang-xie/Wimuse},
abbreviated = {MobiQuitous'21},
thumbnail_path = {/assets/thumbnail_files/wimuse.jpg}
}
WiFi-based sensing has aroused immense attention over recent years. The rationale is that the signal fluctuations caused by humans carry the information of human behavior which can be extracted from the channel state information of WiFi. Still, the prior studies mainly focus on single-task sensing (STS), e.g., gesture recognition, indoor localization, user identification. Since the fluctuations caused by gestures are highly coupling with body features and the user’s location, we propose a WiFi-based multi-task sensing model (Wimuse) to perform gesture recognition, indoor localization, and user identification tasks simultaneously. However, these tasks have different difficulty levels (i.e., imbalance issue) and need task-specific information (i.e., discrepancy issue). To address these issues, the knowledge distillation technique and task-specific residual adaptor are adopted in Wimuse. We first train the STS model for each task. Then, for solving the imbalance issue, the extracted common feature in Wimuse is encouraged to get close to the counterpart features of the STS models. Further, for each task, a task-specific residual adaptor is applied to extract the task-specific compensation feature which is fused with the common feature to address the discrepancy issue. We conduct comprehensive experiments on three public datasets and evaluation suggests that Wimuse achieves state-of-the-art performance with the average accuracy of 85.20%, 98.39%, and 98.725% on the joint task of gesture recognition, indoor localization, and user identification, respectively.
Journal articles
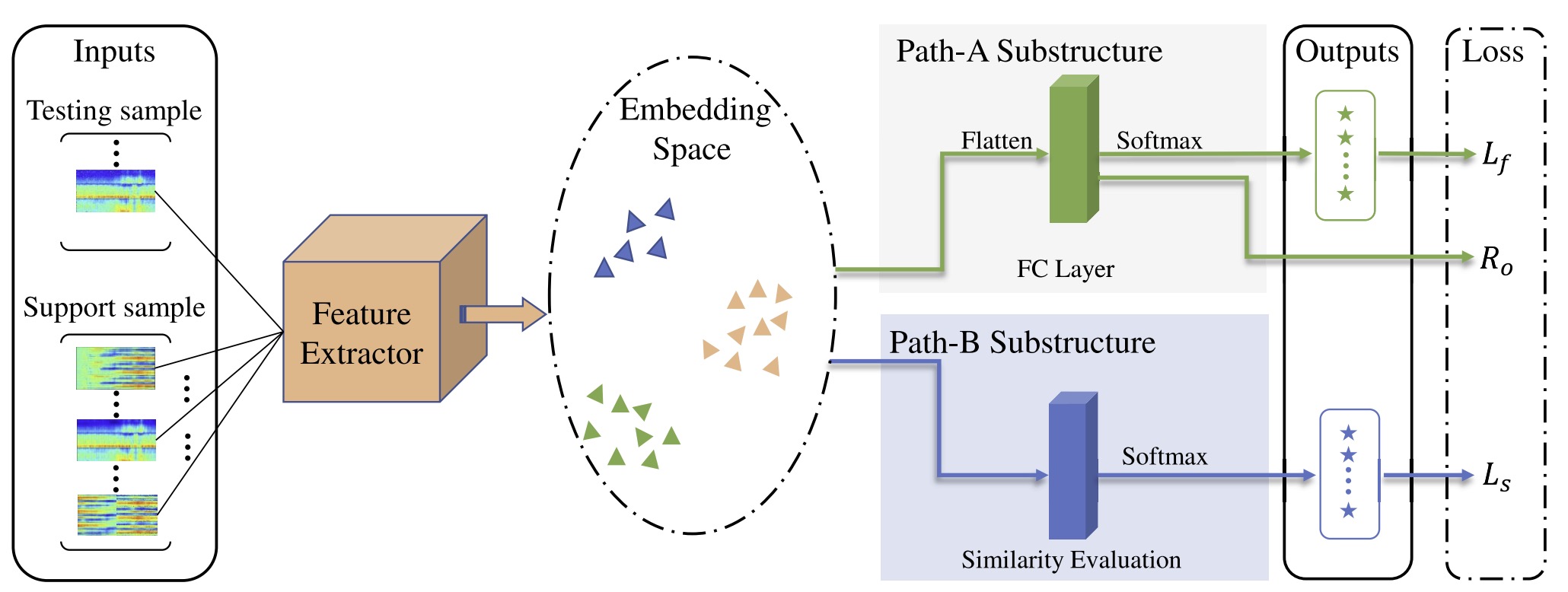
WiFi-based Cross-Domain Gesture Recognition via Modified Prototypical Networks
Zhang, Xie and Tang, Chengpei and Yin, Kang and Ni, Qingqian
IEEE Internet of Things Journal, 2021, pp. 1–1
@article{zhangWiFibasedCrossDomainGesture2021,
title = {{{WiFi-based Cross-Domain Gesture Recognition}} via {{Modified Prototypical Networks}}},
author = {Zhang, Xie and Tang, Chengpei and Yin, Kang and Ni, Qingqian},
year = {2021},
journal = {IEEE Internet of Things Journal},
pages = {1--1},
doi = {10.1109/JIOT.2021.3114309},
file = {/papers/WiGr_zhang.pdf},
code = {https://github.com/Zhang-xie/WiGr},
abbreviated = {IoTJ'21},
thumbnail_path = {/assets/thumbnail_files/wigrIoT.jpg}
}
Numerous deep learning studies have achieved remarkable advances in WiFi-based human gesture recognition (HGR) using channel state information (CSI). However, since the CSI patterns of the same gesture change across domains (i.e., users, environments, locations, and orientations), recognition accuracy might degrade significantly when applying the trained model to new domains. To overcome this problem, we propose a WiFi-based cross-domain gesture recognition system (WiGr) which has a domain-transferable mapping to construct an embedding space where the representations of samples from the same class are clustered, and those from different classes are separated. The key insight of WiGr is using the similarity between the query sample representation and the class prototypes in the embedding space to perform the gesture classification, which can avoid the influence of the cross-domain CSI patterns change. Meanwhile, we present a dual-path prototypical network (Dual-Path PN) which consists of a deep feature extractor and a dual-path (i.e., Path-A and Path-B substructures) recognizer. The trained feature extractor can extract the gesture-related domain-independent features from CSI, namely, the domain-transferable mapping. In addition, WiGr implements the cross-domain HGR based on only a pair of WiFi devices without retraining in the new domain. We conduct comprehensive experiments on three data sets, one is built by ourselves and the others are public data sets. The evaluation suggests that WiGr achieves 86.8%–92.7% in-domain recognition accuracy and 83.5%–93% cross-domain accuracy under the four-shot condition.
Awards & Honors
🎖️ The 13th HLF Travel Grant Award
🎖️ The 13th Heidelberg Laureate Forum (HLF) Young Researcher
🎖️ MobiSys’26 Rising Star
🎖️ Alibaba Cloud Most Scalable AI Solution Award (single-team award, 5000 USD) at the Global AI Challenge 2025
🏛️ Invited Reviewer, APSIPA Transactions on Signal and Information Processing;
IEEE Internet of Things Journal (IoTJ);
Proc. ACM Interact. Mob. Wearable Ubiquitous Technologies (IMWUT);
International Conference on Parallel and Distributed Systems (ICPADS’24);
IEEE Transactions on Mobile Computing (TMC);
🏛️ ACM Transactions on Internet of Things Distinguished Reviewer, TIOT Journal;
Talks
🎙️ Hands-on Tutorial on Thermal Sensing | invited talk 🚩HotSense @ MobiCom 2025 , 📅 2025-11-8, 📍 Hong Kong 🔍 Thermal array sensing for resolving the paradox of ubiquitous thermal signals yet scarce perception systems.
🎙️ TAPOR | conference presentation 🚩UbiComp 2025 , 📅 2025-10-15, 📍 Espoo, Finland 🔍 3D Hand Pose Reconstruction with Fully Passive Thermal Sensing for around-Device Interactions.
🎙️ TADAR | conference presentation 🚩MobiHoc 2024 , 📅 2024-10-16, 📍 Athens, Greece 🔍 Thermal Array-based Detection and Ranging for Privacy-Preserving Human Sensing.
Teaching
🧑🏫 COMP7310, Artificial intelligence of things, Spring 2026
🧑🏫 COMP3270, Artificial intelligence, Fall 2024
🧑🏫 COMP3314, Machine learning, Fall 2023
🧑🏫 CS3230, Operating system, Fall 2022
Rejection Letters
Every paper eventually finds its home, but acceptance is never the end of the research.
Xie ZHANG
(2026) Ph.D. Computer Science, HKU
(2022) M.S. Pattern Recognition and Intelligence Systems, SYSU